Model Bahasa Tingkat Karakter dengan RNN untuk Bahasa Indonesia
Edinburgh,Terinspirasi dari tulisan Andrej Karpathy di blognya yang berjudul The Unreasonable Effectiveness of Recurrent Neural Networks, saya tertarik untuk mengulang eksperimen yang sama dengan bahasa Indonesia. Mengingat bahasa Indonesia tidak terlalu jauh berbeda dengan bahasa Inggris, saya pikir hasilnya juga akan bagus dan menarik. Kalau Anda belum membaca tulisan Andrej tersebut, saya sangat menyarankan Anda untuk membacanya terlebih dahulu. Judul tulisan tersebut tidak berlebihan; siapapun pasti akan terpukau melihat hasil eksperimen yang dilakukan Andrej. Eksperimen dan analisis yang akan saya jabarkan pada tulisan ini juga kurang lebih akan mirip dengan tulisan Andrej.
Sebelumnya, saya perlu menjelaskan sedikit tentang pemodelan bahasa dan recurrent neural network (RNN). Jika Anda sudah memiliki pemahaman akan kedua hal ini (misalnya setelah membaca tulisan Andrej tadi), silakan saja jika ingin melewatkan kedua bagian ini. Penjelasan yang akan saya berikan hanya berupa gambaran umum dan serupa dengan penjelasan Andrej di tulisannya. Jika Anda sudah tidak sabar dan ingin langsung mencoba dengan melihat kode implementasi, Anda dapat mengaksesnya di repositori ini.
Pemodelan Bahasa
Pemodelan bahasa adalah salah satu permasalahan penting di bidang pengolahan bahasa manusia [1]. Dalam permasalahan ini, kita ingin memberikan nilai peluang pada barisan-barisan kata dalam suatu bahasa. Barisan-barisan kata ini dapat dipahami sebagai kalimat, paragraf, atau bahkan satu wacana sekaligus. Untuk menyingkat penulisan, mulai sekarang saya akan menyebut kalimat saja. Diberikan sebuah kalimat \(s\) yang merupakan untaian kata-kata \(\{ w_i \}_{i=1}^n\), peluang kalimat tersebut adalah
Perhatikan bahwa peluang suatu kalimat didefinisikan sebagai peluang gabungan dari kata-kata penyusunnya. Persamaan di atas hanyalah penjabaran dari aturan perkalian peluang gabungan. Ruas kanan persamaan ini mengandung suku \(P(w_i | w_{i-1}, \ldots, w_1)\), yakni peluang bersyarat suatu kata jika diberikan kata-kata pendahulunya dalam kalimat \(s\). Dari sini terlihat bahwa pemodelan bahasa dapat dipandang sebagai permasalahan pemodelan peluang bersyarat ini.
Meski pada umumnya model bahasa memodelkan peluang kata, tidak ada larangan untuk memodelkan peluang karakter atau huruf; lagipula, kalimat juga dapat dipandang sebagai untaian karakter, bukan? Itulah yang dimaksud dengan model bahasa tingkat karakter dan model inilah yang digunakan oleh Andrej. Model ini juga yang akan saya gunakan dalam eksperimen ini.
Recurrent Neural Network
Recurrent neural network (RNN) adalah salah satu varian dari model jaringan saraf tiruan yang mampu memodelkan dependensi sekuensial pada data masukan. Kemampuan ini disebabkan oleh adanya koneksi simpul (recurrent) pada model. RNN memproses masukan secara sekuensial. Pada tiap langkah waktu, masukan dari RNN tidak hanya data masukan asal tapi juga nilai dari lapis tersembunyi [2] pada langkah waktu sebelumnya. Ilustrasi arsitektur RNN ini dapat dilihat pada gambar di bawah.
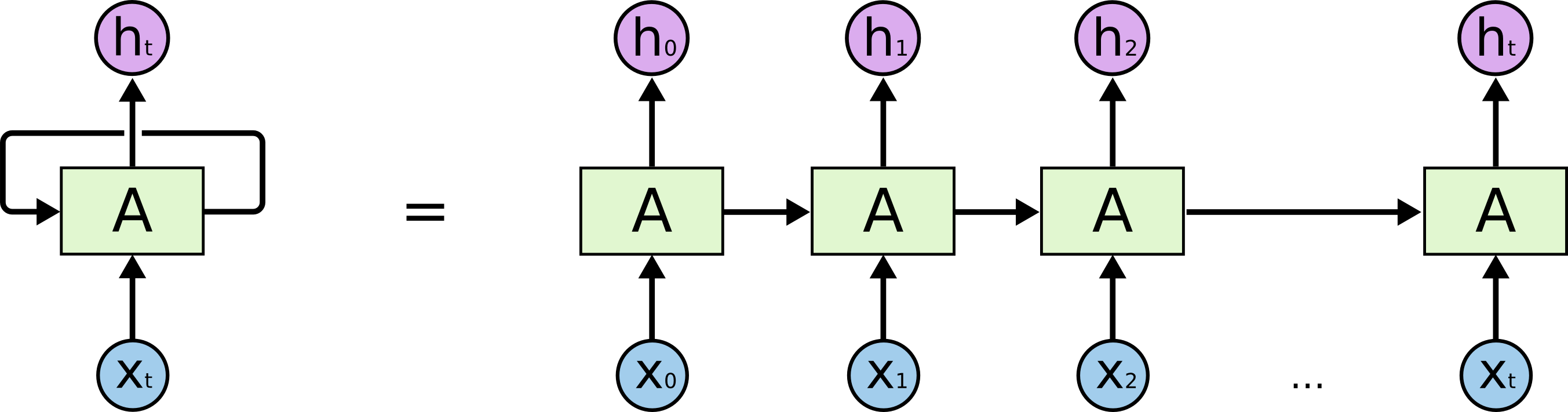
Diagram dari arsitektur RNN dengan koneksi simpul (kiri) dan arsitektur RNN ketika koneksi simpul direntangkan (kanan). (sumber: https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
Bagian kanan gambar di atas mengilustrasikan arsitektur RNN ketika koneksi simpulnya direntangkan. Gambar tersebut menunjukkan bahwa koneksi simpul pada RNN tidaklah spesial; ia dapat direntangkan sehingga menghasilkan arsitektur yang tidak jauh berbeda dengan jaringan saraf tiruan biasa yang tidak mengandung simpul. Hal penting yang juga perlu diperhatikan adalah RNN memberikan keluaran pada setiap langkah waktu. Keluaran pada suatu langkah waktu ini hanya dipengaruhi oleh masukan-masukan pada langkah-langkah waktu sebelumnya. Hal ini membuat RNN berguna dalam pemodelan bahasa. Mengapa? Ketika menuturkan kalimat, secara tidak sadar, kata-kata yang telah kita ucapkan akan menentukan kata yang akan diucapkan berikutnya. Sebagai ilustrasi, melihat potongan kalimat “saya makan”, kita cukup yakin bahwa kata “nasi” lebih berpeluang ketimbang kata “panas” sebagai kata berikutnya. RNN cocok dalam pemodelan bahasa karena pada setiap langkah waktu, keluaran dari RNN dapat dipandang sebagai prediksi atau peluang suatu kata setelah kata-kata sebelumnya pada masukan telah muncul. Peluang ini adalah peluang bersyarat seperti yang telah dijelaskan pada bagian pemodelan bahasa sebelum ini. Fakta ini tetap berlaku meskipun kita “bermain” di tingkat karakter.
Salah satu varian RNN yang populer digunakan dalam pemodelan bahasa adalah long short-term memory network (LSTM) [3]. Seperti Andrej, saya menggunakan LSTM dalam eksperimen yang saya kerjakan. Pada tulisan ini saya tidak akan menjelaskan lebih lanjut tentang RNN maupun LSTM. Anda dapat mengetahui lebih lanjut dengan membaca tulisan dari Chris Olah yang sangat bagus ini.
Pemodelan Bahasa Tingkat Karakter dengan LSTM
Untuk memodelkan bahasa di tingkat karakter menggunakan LSTM, kita cukup mengganti masukan dari kata menjadi karakter. Keluaran dari LSTM sekarang dapat dianggap sebagai prediksi karakter berikutnya diberikan kemunculan karakter-karakter sebelumnya. Diagram di bawah ini menunjukkan bagaimana proses ini berlangsung.
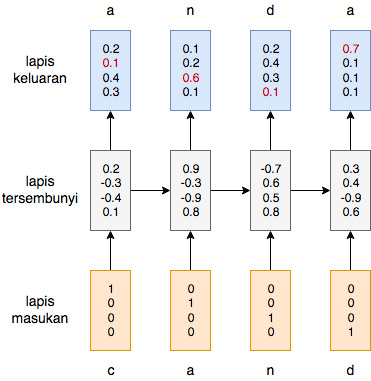
Pemodelan bahasa tingkat karakter dengan menggunakan LSTM untuk kata masukan ‘canda’. Masukan dari LSTM ini adalah representasi one-hot encoding dari karakter. Keluaran dari LSTM ini adalah distribusi peluang bersyarat dari karakter selanjutnya jika diberikan karakter-karekter yang muncul sebelumnya. Entri berwarna merah pada keluaran adalah peluang dari karakter berikutnya yang diharapkan.
Diagram di atas mengilustrasikan proses yang terjadi ketika kita ingin memodelkan karakter pada kata “canda”. Masukan pada setiap langkah waktu adalah representasi vektor dari huruf “c”, “a”, “n”, dan “d” berturut-turut. Representasi vektor dari karakter-karakter ini didapat dengan menerapkan *one-hot encoding* pada karakter-karakter tersebut. Perhatikan bahwa kita punya 4 karakter unik (“c”, “a”, ‘n”,”d”) sehingga dimensi dari masukan juga 4. Setiap elemen dari vektor pada masukan berkorespondensi dengan salah satu dari 4 karakter tersebut; elemen pertama adalah karakter “c”, kedua adalah “a”, dan seterusnya. Oleh karena itulah karakter “c” direpresentasikan dengan vektor \([1 ~ 0 ~ 0 ~ 0]^{\top}\), “a” dengan \([0 ~ 1 ~ 0 ~ 0]^{\top}\), dan seterusnya. Keluaran dari LSTM ini adalah distribusi peluang dari karakter berikutnya. Elemen yang diberi warna merah adalah peluang dari karakter yang benar. Kita ingin peluang-peluang berwarna merah ini bernilai sebesar-besarnya dan peluang-peluang lainnya yang berwarna hitam bernilai sekecil-kecilnya. Inilah yang dilakukan dalam proses pelatihan LSTM. Fungsi objektif yang diminimumkan pada saat pelatihan adalah negative log likelihood dari data pelatihan kita.
Satu hal yang unik dari pemodelan bahasa ini adalah pelatihannya tidak membutuhkan data yang telah dilabeli secara manual. Pelatihan model bahasa dapat dilakukan dengan data tekstual apa saja tanpa label apapun. Hal ini menjadi penting terutama untuk bahasa-bahasa dengan sumber daya rendah seperti bahasa Indonesia. Sulitnya mendapatkan data berlabel membuat permasalahan pengolahan bahasa manusia dalam bahasa Indonesia juga sulit dikerjakan. Namun, karena data tekstual bahasa Indonesia tanpa label dalam jumlah besar mudah didapatkan (dari situs-situs berita daring misalnya), permasalahan pemodelan bahasa Indonesia menjadi jauh lebih mudah untuk dikerjakan.
Dataset
Dalam eksperimen yang saya kerjakan, saya menggunakan koleksi artikel berita daring yang dirilis oleh University of Amsterdam. Dataset ini mengandung artikel-artikel daring dari Kompas dan Tempo dari sekitar tahun 2000–2002. Ada sekitar 49 juta karakter yang terdapat pada dataset ini. Saya menyisihkan sebagian dataset sebagai data validasi. Karakter-karakter pada data pelatihan yang muncul kurang dari lima kali saya ganti dengan token spesial untuk karakter-karakter langka/tidak diketahui. Proses ini mengatasi masalah adanya karakter baru yang tidak muncul di data pelatihan sebelumnya namun muncul di data validasi. Total ada sekitar 87 karakter unik pada data pelatihan. Data pelatihan dan validasi diproses paragraf per paragraf.
Implementasi dan Eksperimen
Saya menggunakan LSTM dengan 2 lapis tersembunyi, masing-masing memiliki 200 unit tersembunyi, sehingga total parameter ada sekitar 570 ribu. Keluaran dari LSTM diberikan sebagai masukan untuk lapis linear yang memetakan 200 dimensi keluaran ke 87 dimensi, yaitu sebanyak karakter unik yang ada pada data pelatihan. Untuk menghindari overfitting, saya menggunakan dropout dengan peluang 0.2. Saya menggunaan kelas torch.nn.LSTM dan torch.nn.Linear yang disediakan oleh pustaka PyTorch sebagai implementasi dari LSTM dan lapis linear tersebut. Saya melatih LSTM dengan menggunakan stochastic gradient descent selama 4 masa [4] dengan ukuran minibatch sebesar 32 dan aturan pembelajaran Adam dengan laju pembelajaran sebesar 0.001. Saya menggunakan kelas torch.optim.Adam sebagai implementasi dari aturan pembelajaran ini. Gradien dari parameter model dipangkas pada besaran norm 5 untuk mencegah masalah pembengkakan gradien [5] yang lazim terjadi pada pelatihan LSTM. Proses pelatihan dieksekusi pada mesin tipe p2.xlarge (dengan GPU) yang ditawarkan oleh Amazon Web Service dan memakan waktu sekitar 20 jam. Seluruh kode implementasi dapat diakses di repositori ini.
Hasil dan Analisis
Berikut adalah beberapa paragraf yang dihasilkan oleh LSTM setelah dilatih. Paragraf-paragraf di bawah ini dihasilkan dengan memberikan potongan kecil teks sebagai masukan untuk LSTM lalu membiarkan LSTM melanjutkan hingga mendapatkan satu paragraf penuh. Potongan teks yang dicetak tebal pada awal paragraf adalah potongan kecil masukan tersebut.
Cinta adalah mereka berharap Kapolda terbatas pukul putus di Jakarta Selatan. “Dia mengakui massa agar strategi, Kamis (1/5).”Kalau bila ditolakles sebagai piata di Jalino Johnso sudah meladukan penyerangan dan menyediakan bantuan sebagai Tempo Serta Baru. May dan masalah keras untuk berjalan seperti ini. Begitu punya krisis antara sebesar 15 persen akan mengatakan beberapa bulan,” ujarnya. Menurut mereka, dengan kabupaten merupakan soal industri untuk menjalani apalagi bahwa pertemuan, tanpa para ini menanyakan, para Bunga yang tidak berhak menjelaskan oralitas dari Direktur Utama yang dikemukakan Kejaksaan Agung, Yukudin dan Wimarrono, adalah Tutun Wiranto berdasarkan dirisyawat.
Korban bernama John Tata, Gus Dur untuk saja dibilar dengan waktu, kemudian adalah tukarnya milik Gereja Rusiar. Dalam-votikan penambahan masyarakat masih berdialah. Demikian Sidang Tahu Taliban Naswurja, sebagai teknologi yang tak ikut membunuh warga Kecamatan Silam Hilal dilaksanakan di badan esris Lealina Australia. “Maka yang menunjukkan membuat bentuk keamanan mau. Namun, kabinetlon cantaulis, bahkan terkedu-berita yang mempertimbangkan dua orang mislim sebenarnya tidak tahu prasarcoya, seperti itu tidak bentu yang tadi,” ujarnya.
Kedua pasangan baru saja sekarang bisa dihimpun berada di batu Jabir. Jalat penumpang sekali tetih hanya bernama Tektif. Akhir hari ini dirakan dengan anggota KPD dalam sikapnya yang dilengkapi sudah kebutuhan penahanannya.
Terlihat bahwa LSTM cukup sukses dalam memproduksi paragraf yang mirip dengan artikel berita. LSTM mampu belajar aturan-aturan sintaksis seperti kalimat haruslah diakhiri titik dan diawali huruf kapital. Selain itu, LSTM sepertinya juga mampu menghasilkan kalimat dengan tata bahasa yang lumayan baik, meski arti dari kalimatnya masih tidak jelas. Hal penting lainnya adalah LSTM juga mampu menghasilkan kutipan langsung dan keterangan hari dan tanggal dengan gaya penulisan seperti artikel berita pada umumnya. Menarik sekali!
Proses Belajar LSTM
Bagaimana proses belajar LSTM ini? Mengikuti analisis Andrej, saya akan jabarkan beberapa sampel hasil produksi LSTM pada berbagai iterasi pelatihan. Satu iterasi di sini adalah satu kali pembaruan parameter model dengan satu minibatch data.
Pada iterasi 0, ketika parameter model baru saja diinisialisasi secara acak dan belum ada proses pembaruan, LSTM memproduksi paragraf seperti ini:
-9sg5R4”DQKZeY+$rj(aoO%+;@JCJhk*1@D*pcGdFwagQbl+tw/vNM/HqiEbVP-‘vm-zZ@OP9gX
Hasil ini benar-benar acak. LSTM sama sekali belum belajar konsep kata maupun kalimat. Karakter-karakter yang tidak lazim dalam bahasa Indonesia seperti “@” atau “*” pun seringkali muncul.
Pada iterasi 200, hasil sudah mulai membaik:
j.ar sta,a bewaeg,kn pakuura ilra be. )tia jaseduP dedri fAdam.Ijaman jisua umim(ni Iake -,ata gPsn raken tinmKmottmomtit Pegineten0ay mameMnh)aa ig sala
LSTM sudah tidak lagi menghasilkan karakter-karakter tidak lazim. Ia juga mulai belajar konsep kata: untaian karakter yang dibatasi oleh spasi. Meski demikian, kata-katanya masih sangat kacau dan kadang mengandung karakter yang tidak semestinya.
Pada iterasi 2.000, hasilnya semakin bagus:
Makho makinan han menpra pengitara pelkasian patar. “atiu tidak 1094 menyet begar 1406. Polek kanti PU dun EIruai meneras derbat patunya Akdi menarit kitu Kodar Ketimua Indem Idorang, kekulang rendakaran belank,” katarto kati fumatin semajiknya. Ine ila Olumbod, dan Nasia, rehara telah meryasukan sajalah butor tidaknas ters osat calen sodik sesognk Moss bungan, bernadhan inherni.
Paragraf sudah semakin panjang. LSTM juga sudah mulai paham konsep kata dan mulai beralih ke konsep kalimat: untaian kata yang diakhiri oleh tanda titik dan diawali dengan huruf kapital. LSTM juga mulai belajar tentang kutipan langsung dan nama-nama yang mesti diawali huruf kapital.
Pada iterasi 4.800, LSTM menghasilkan paragraf:
Bor Avies EPS Selatan Santio Kewuat Agrokt Suloyo, kare laktian makip menceniskan siusaya mengakuki tinggal dan persakapan di interbet. Selain itu, Mizto, Ketua Mebor Agu Pollang, Pemerintah Kalau Bulis, di pastrak-Manorian dalam akan mendasas Tenup. “it inerasnif cini sekipar 6,34 telas lepiting. Kire berat berpemajukan dari akses dan apakah sebesar pirahak dengan perahaman 22.60 honatal.”Soal Presiden mengelami dan merekang Suar dan Masionluso (Prub) 198, anontari, kehakingan dusukan atau sebagain-kehurani Rp 41.000 gumat Rp 2 trilih di Bingkar yang luruh bis Rpo. Usung Lursakan Sangku. Keperbihaan mereka menjengar bererolok massa yang rapiti cupuk masyarakaput “Pasfasi seurat dipiduk direcaran tukai. Kayangan mekologisa yang tidak juga genjung orang untuk menjadi ke menghelaskan. Menurut sulam kantor Rp 1 triliun yang membasari 1.005 juta mengaru gempak, dan inverningan, dan perkarian tewar harga berapa wakru yang rimet menyeburkan UU orang disebutani Golmad Darair di penaman Imenteri. Namun dibunaskan harkas 1..00 W Hiternah minca adanya diakuiman.
Sekarang paragraf sudah lebih panjang dan LSTM juga mulai menghasilkan kata-kata dalam bahasa Indonesia yang benar. LSTM juga mulai belajar tentang penulisan angka dan uang.
Pada iterasi 9.600, hasilnya adalah:
Panjung sebuah kekuastan aktif mengingatkangkan orasi di Jakarta. Gustrasi terhadap tetap pakit menginginkan ondon. langsung, sati-aken di lokasi Jevry yang lalu bika dalam keputusan awang yang mengelola senjata pintung, merusakkan tugas adalah Ruara panggilan wakil bulan di Kauran Gredek akhirnya 10 tahun, 30 juta. Kaling berkuasa bukan dengan pelanggalan sepanjang oleh RS. Isa, menurut Dewan Kepala Umur 1948. Menurut Gus Dur, dari Irtukutan Ambon, bahka tidak ada pembenaran tepan mengakui,” katanya.
Terlihat bahwa ada lebih banyak kata-kata dalam bahasa Indonesia dan penulisan tahun, uang, dan nama tempat juga sudah baik.
Iterasi ke-14.100, LSTM menghasilkan:
Para untuk mantan Pansus Waliya yang terus ke tahu ontovisian redekati Radyati Pancal dan Fapbarjo, Infamemil Pusat Indonesia (NU/), jatuh Rp 20.300 per (Abdul Davis). Jumlah pukul 05.05 WIB, maka dadaran instruksi industri itu segera sudah oleh Departemen Austrulia. Masyarakat persoalan Airkasi Polda MPR (ITAi) Opgriontoh Indonesia berdiang. Instreksi penuntutan tersebut akan menyalahkan partai/polisi, tidak meloncar atas nol sifatnya.
Kata-kata dalam bahasa Indonesia semakin banyak. Penulisan dengan tanda kurung juga muncul lebih sering dan LSTM tidak lupa untuk menghasilkan kurung tutup setelah kurung buka. LSTM juga menghasilkan penulisan waktu yang sempurna. Perlu diperhatikan juga bahwa kata-kata yang bukan dalam bahasa Indonesia pun sekarang sudah tidak sekacau sebelumnya. Kata-kata ini sudah lebih terlihat seperti kata-kata bahasa Indonesia yang valid.
Pada iterasi terakhir, paragraf yang dihasilkan adalah:
Ketu Deppentalik KBP Makangana (GAM) Ekbia/Raya Minggu saat ditutup pada bomman atas rombongan ASPS anggaran lainnya dipoteng oceh untuk menempuh bangsa kepurungan untuk menentukan penyaluran obdi itu diperkirakan hingga kejutan. Irega siapa yang sedang mungkin masuk ke Jakarta. Tampak menegaskan ‘Presiden mengkontrat Kanine Sajarin telah dibandikan. “Untuk konstitusi atau surat inisikatif dalam melakukan perempuan kesehatan. Sebagai pengemberian bangsa di DPR nyarti ini ada, semua karena masih ada wania seruas tersebat,” kata Syariah Yuni. Miara akan dilihat dalam pihak Ozdur yang sama untuk melanjalkan dunia oleh Seping Soeharto untuk mengerous tulihan itu.
Paragraf ini sudah lumayan mirip dengan tipikal paragraf di suatu artikel berita. LSTM sudah belajar konsep kata, kalimat, nama-nama, dan kutipan langsung, serta mampu merangkainya menjadi sebuah paragraf. Meski demikian, LSTM ini masih tidak dapat menghasilkan paragraf yang koheren dengan gagasan utama yang jelas. Hal ini mengisyaratkan bahwa pemodelan bahasa tingkat karakter mungkin kurang cocok dalam menangkap konsep topik. Dan hal ini masuk akal karena untuk bicara soal topik, maka kita perlu bicara soal kata-kata yang menyusun topik tersebut dan bagaimana kata-kata tersebut dirangkai.
Kesimpulan
Berdasarkan hasil eksperimen yang saya lakukan, RNN, yang diwakili oleh LSTM, sepertinya cocok untuk memodelkan bahasa Indonesia di tingkat karakter. Dengan proses pelatihan yang tergolong singkat, LSTM mampu mempelajari konsep-konsep linguistik seperti kata dan kalimat serta mampu menggunakan konsep-konsep tersebut untuk menghasilkan sebuah teks yang mirip dengan tipikal teks dalam bahasa Indonesia. Meski demikian, RNN tingkat karakter tidak mampu menangkap konsep linguistik di tingkat yang lebih tinggi seperti topik. RNN tingkat kata mungkin bisa menjadi alternatif untuk kebutuhan ini.
Demikianlah tulisan saya tentang eksperimen pemodelan bahasa tingkat karakter dengan RNN untuk bahasa Indonesia. Semoga tulisan ini bermanfaat bagi Anda!
| [1] | Terjemahan dari natural language processing. Meski terjemahan yang mungkin lebih sering digunakan adalah “pemrosesan bahasa alami”, saya menggunakan terjemahan dari mata kuliah yang saya ambil di Fasilkom UI. Saya lebih setuju dengan penggunaan kata “manusia” daripada “alami” karena, seperti yang dosen saya pernah katakan, “alami” terkesan mencakup bahasa selain bahasa yang digunakan manusia. Padahal, natural language processing eksklusif membahas bahasa manusia saja. |
| [2] | Terjemahan dari hidden layer dalam bahasa Inggris. Dari hasil pencarian saya, sepertinya belum ada padanan yang sudah diterima untuk istilah ini. Orang-orang banyak menggunakan “lapisan tersembunyi” atau “lapis tersembunyi”. Saya memilih yang kedua karena terdengar lebih sedap di telinga. |
| [3] | Saya cukup bingung memikirkan terjemahan yang pas untuk istilah ini. Terjemahan yang langsung terpikir adalah “jaringan memori jangka pendek panjang”, tapi terdengar sangat janggal karena adanya dua kata yang berlawanan arti dan diletakkan berurutan. |
| [4] | Terjemahan dari epoch, yakni satu sapuan ketika semua sampel pada data pelatihan telah digunakan untuk memperbarui parameter. |
| [5] | Terjemahan dari exploding gradient. Permasalahan ini terjadi ketika nilai norm dari gradien parameter semakin membesar seiring berjalannya proses pelatihan. Terjemahan ini saya buat sendiri karena sepertinya belum ada terjemahan bahasa Indonesia yang pas untuk istilah ini. |